OpenAMのログをPentaho DIで処理してみる
2021-03-05 - 星野 康

1. はじめに
=== この記事は、以前Qiitaに挙げていたものの再掲です ===
OpenAM 13では、アクセスログや認証ログがCSV形式で出力されます。 プロジェクトによっては、ログに対して以下のような処理が必要とされる場合があります。
- ログ解析ソフトが読み取れる形式に前処理する必要がある。
- 特別な解析をしたい。
上記のような処理の実現は、弊社ではなくてシステム全体纏めのSIer様の領域ですが、「OSSのデータ処理ツールが既にいくつも存在するから、それを使えば楽なのでは…」と思う場面が何度かありましたので、こんな風にできるよという紹介記事を書いてみます。 今回取り上げるデータ処理ツールとしては、Pentaho DI(Data Integration)とします。
2. 実施
2.1 前提など
前提として、弊社版のOpenAM 13のログを利用することとします。 また、今回実施したい処理のシチュエーションとしては、「各人が過去に何回ログインしたかを知りたい」とします。
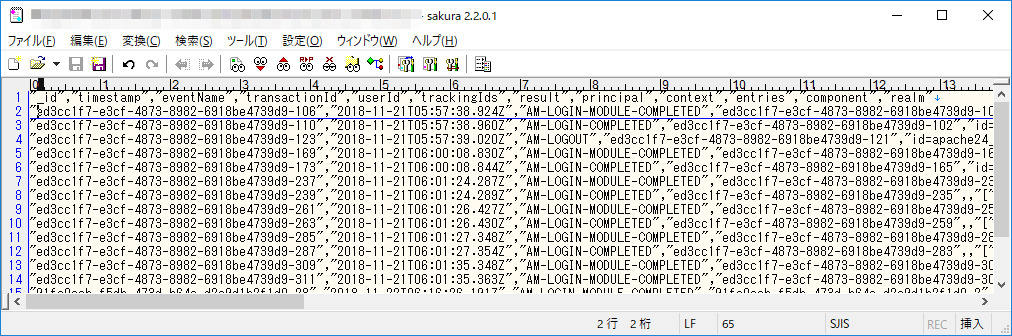
扱うログは、今回は認証結果を扱うので「authentication.csv」が対象となります。デフォルトでは、/opt/osstech/var/lib/tomcat/openam/openam/log/authentication.csv に出力されています。 データの内容は以下のようなもので、1行目にラベルがあり、2行目以降に認証の成否情報が出力されていきます。
2.2 Pentaho DIのダウンロード&インストール
Pentaho DIは、以下のサイトからダウンロードして利用できるOSSです。 https://sourceforge.net/projects/pentaho/files/latest/download (Apache License 2.0) 今回は、バージョン8.1.0.0-365を利用します。
Pentaho DI は Javaプログラムなので、パッケージとしてのインストールは必要なく、zipをダウンロードして展開するのみです。Java実行環境(JRE/Java Runtime Environment)は、別途インストールしておく必要があります。
2.3 Pentaho DI(の処理設計ツール)を起動
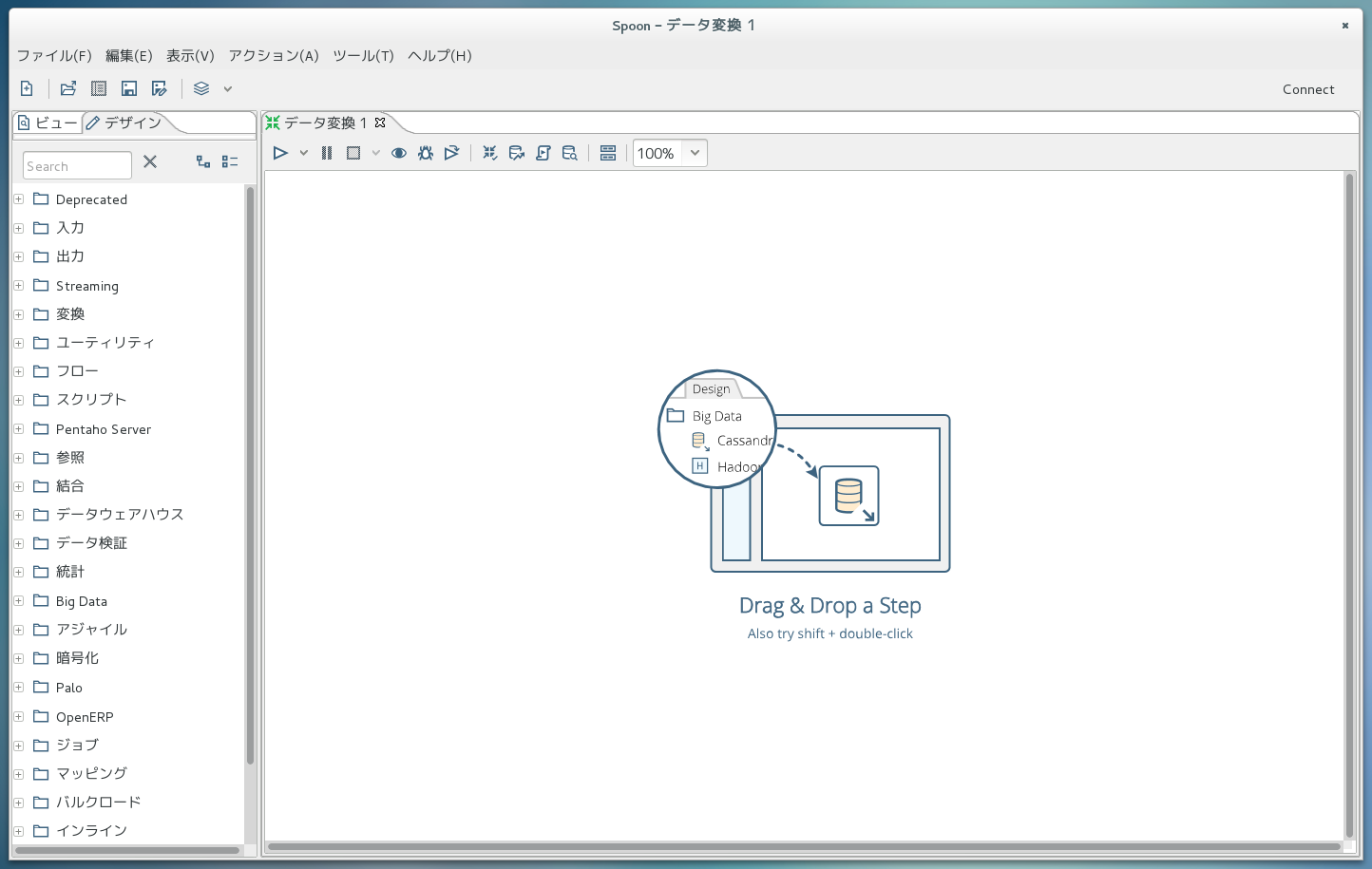
zipを展開した中にあるspoon.sh(Windows環境ならSpoon.bat)を実行すると、処理設計ツール画面が出てきます。 画面左側の「データ変換」をクリックするとデータ変換処理を設計する画面に切り替わり、さらに左側の「デザイン」タブをクリックすると、使える処理部品がずらずらっと出てきます。
2.4 処理を設計(入力)
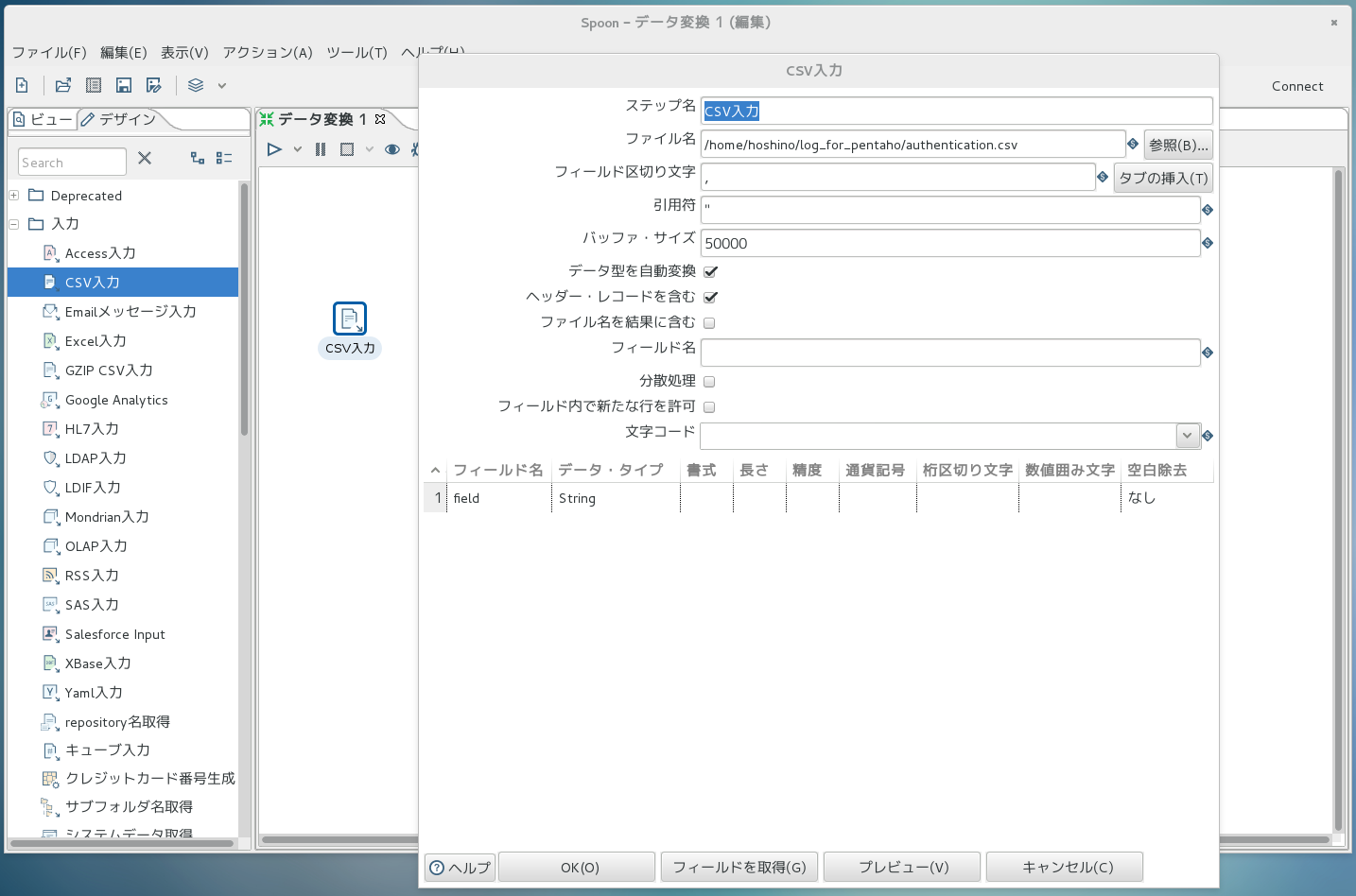
まずはログファイルを読み込む処理を作ってみます。 画面左側から「入力->CSV入力」をドラッグし、右側の任意の場所にドロップします。右側に出来上がったアイコンをダブルクリックすると以下の図のようにダイアログが開き、「CSV入力」部品の動作設定ができます。 今回は、ファイル名の設定のみで十分です。
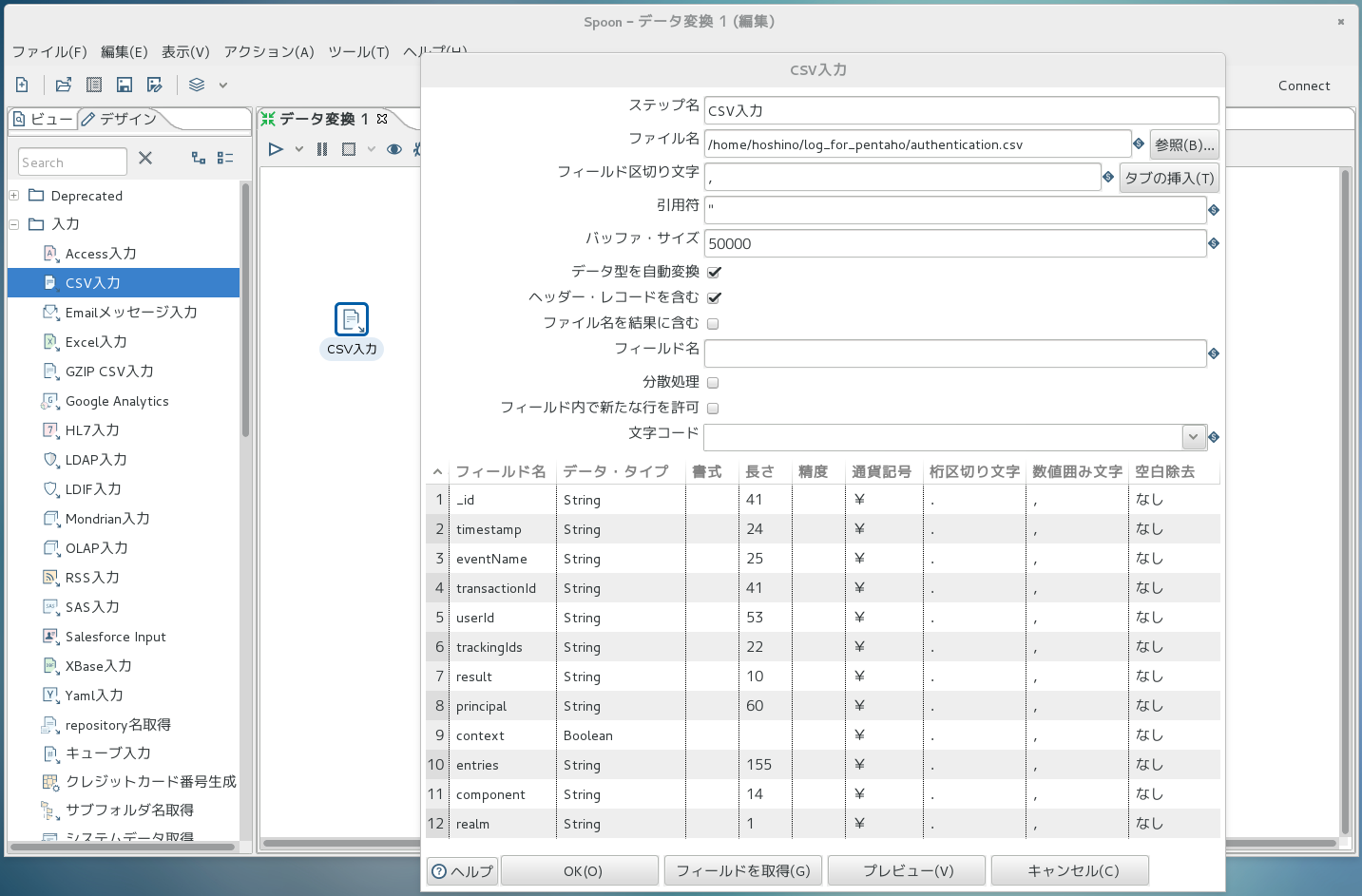
ここで、下部の「フィールドを取得」を押すと、以下の画面例のように、フィールド名・型・長さなどを 自動判別してくれます。 ただし、String型の長さは実際には可変のものが多いと思いますので、自動判別された長さは全部削除してしまうと良いです。
また、ダイアログボックス下部の「プレビュー」ボタンを押すと、実施した設定に従ってファイルを読み込んだ結果を見ることができます。
2.5 処理を設計(必要な行の絞り込み)
今回は認証の成功情報を取り出したいので、eventName列の値が「AM-LOGIN-COMPLETED」であり、かつresult列の値が「SUCCESSFUL」である行で絞り込んでいきます。
さきほどと同様に、今度は「フロー->フィルター」部品をドラッグ&ドロップします。 ここで、右側画面の「CSV入力」のアイコン上で「Shift + クリック」すると矢印がニョキっと出るようになり、 「フィルター」のアイコン上でクリックして「ステップのメインアウトプット」を選択することで、矢印が固定されます。 このように処理部品間を矢印で繋いでいくことで、処理の流れを決めていくことができます。
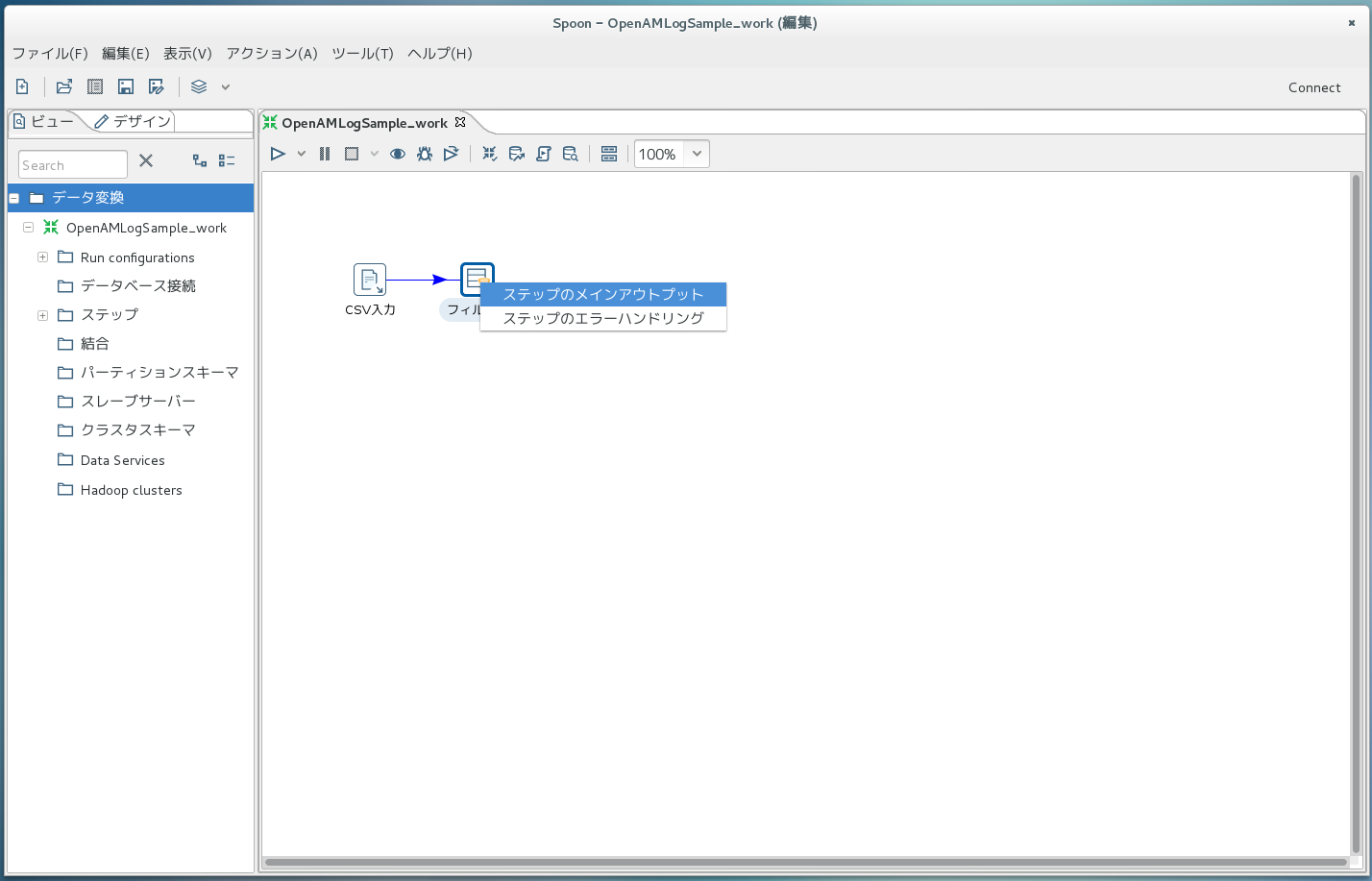
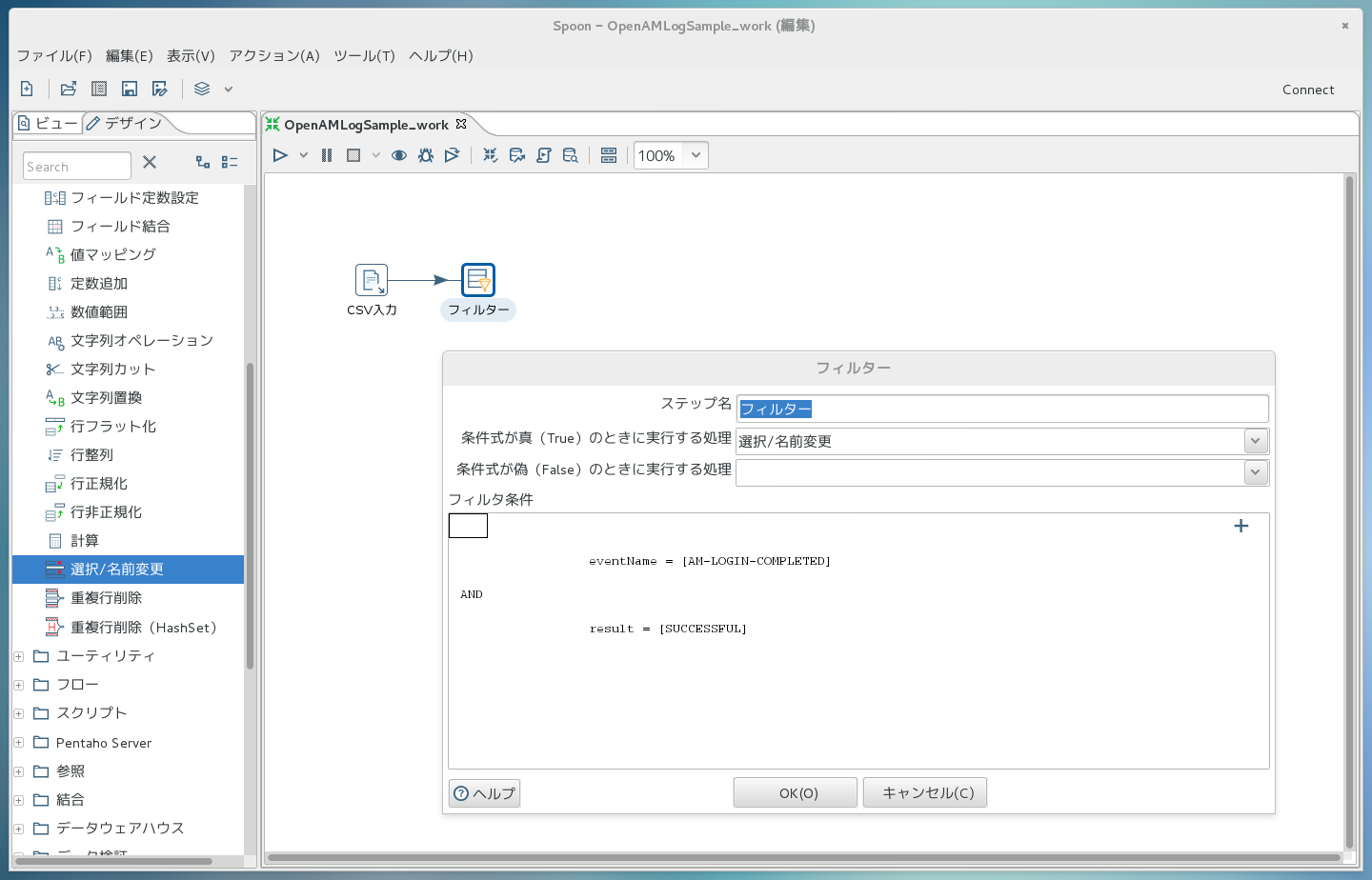
次に、「フィルター」のアイコンをダブルクリックし、出てきたダイアログボックス内で<field>の部分を「eventName」に、<value>の部分を「AM-LOGIN-COMPLETED」にします。
さらに、ダイアログボックス内右上の「+」を押して条件を追加し、<field>の部分を「result」に、<value>の部分を「SUCCESSFUL」にします。
2.6 処理を設計(必要な列の絞り込み)
次に、必要なデータ列のみに絞り込みます。
先ほどまでと同様に、今度は「変換->選択/名前変更」部品を右側にドラッグ&ドロップします。 これも先ほどと同様ですが、「フィルター」のアイコン上で矢印を出し、「選択/名前変更」のアイコン上をクリックして「Result is TRUE」を選択します。 これで、フィルター条件がTRUEのデータのみが「選択/名前変更」の処理に流れていくことになります。
次に、「選択/名前変更」のアイコンをダブルクリックし、「フィールドの選択」ボタンを押します。 すると、この処理部品に流れてくる列名の一覧が出てくるので、必要な列以外をDeleteキーで削除していきます。 今回はprincipal(ユーザ名)のみを残します。
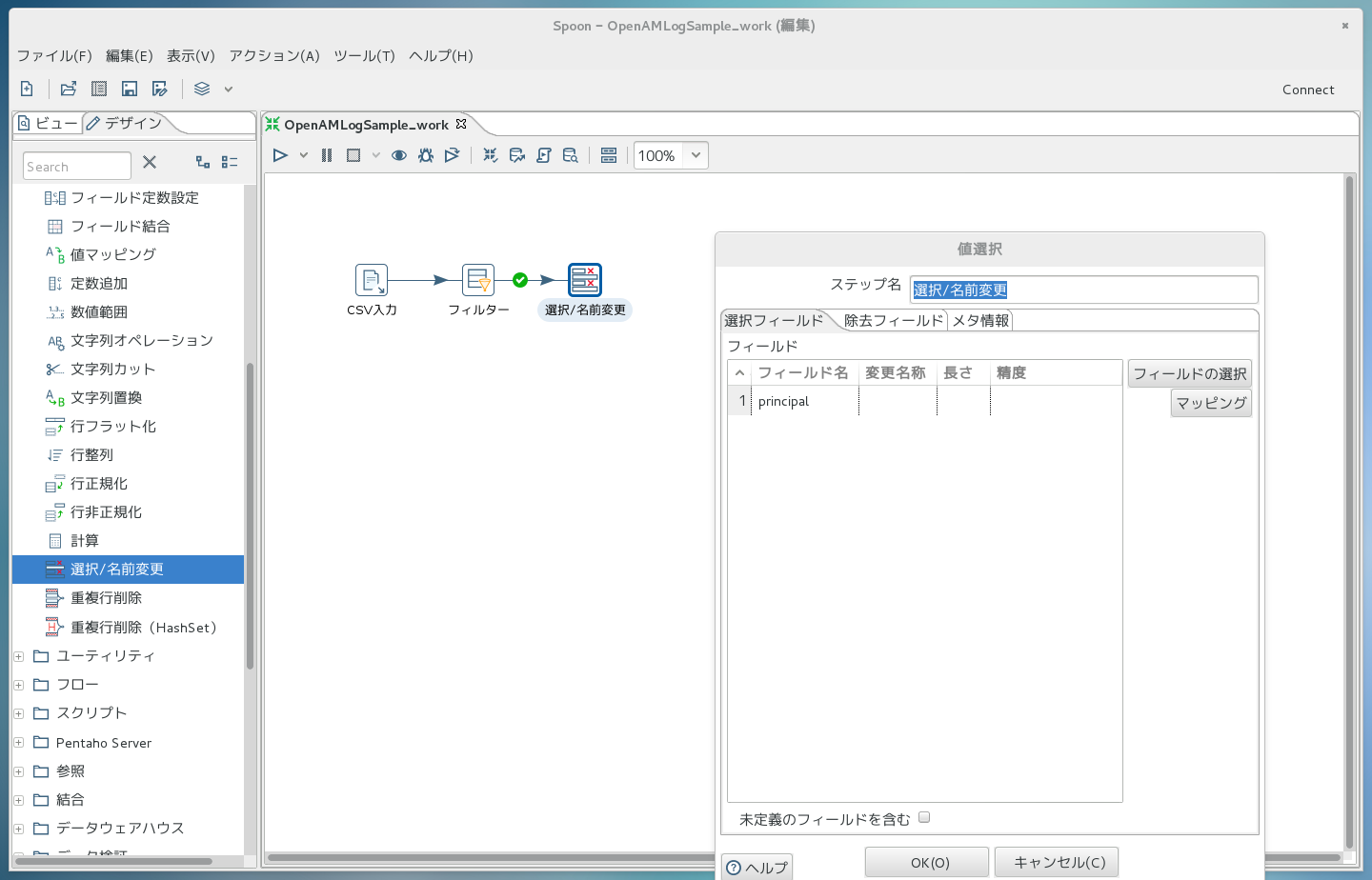
2.7 処理を設計(集計)
ログイン回数の集計処理を行います。
先ほどまでと同様に、今度は「統計->メモリーグループ化」部品を右側にドラッグ&ドロップします。 矢印も繋いでおきます。 次に、「メモリーグループ化」のアイコンをダブルクリックしてダイアログを開き、下記画面のように集計方法を定義します。ユーザ名毎に出現回数を数えて、countというフィールド名で値を保持するということを意味しています。
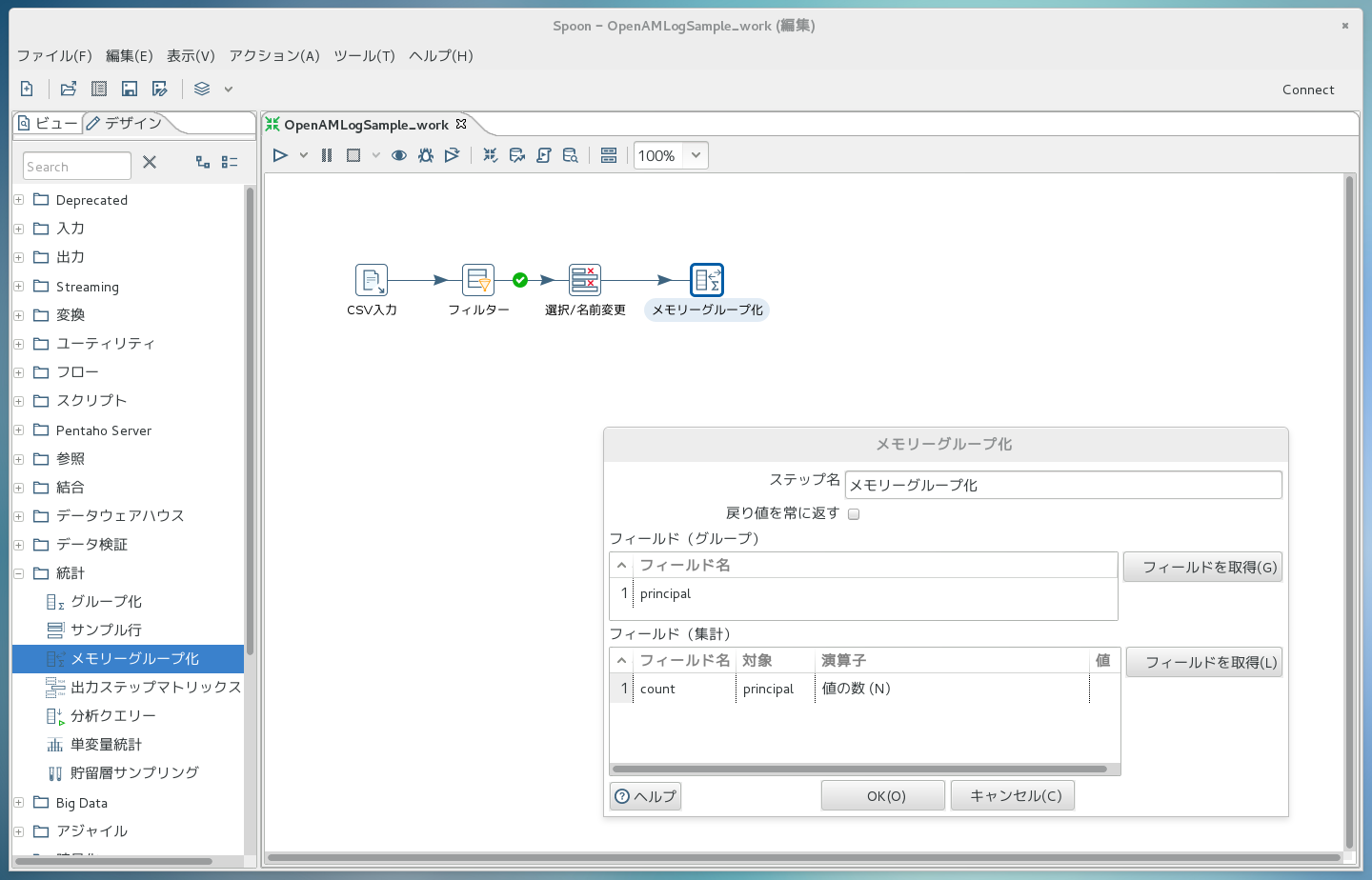
2.8 処理を設計(出力)
処理結果をファイルに出力することにします。
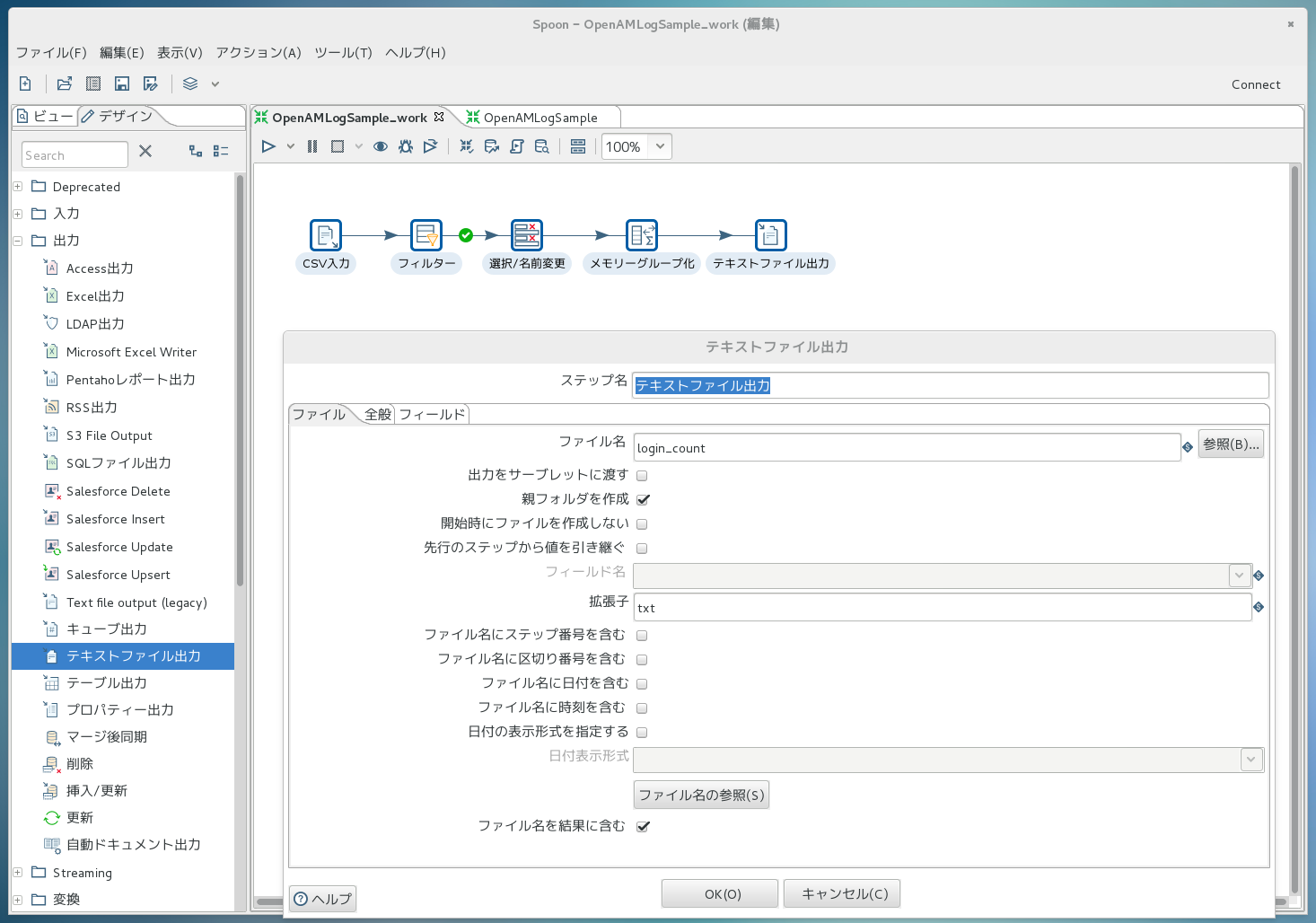
先ほどまでと同様に、今度は「出力->テキストファイル出力」部品を右側にドラッグ&ドロップします。 矢印も繋いでおきます。 次に、「テキストファイル出力」のアイコンをダブルクリックしてダイアログを開き、下記画面のように出力方法を定義します。ここではファイル名だけ設定しています。
2.9 処理を実行
このように、既存の部品をペタペタ並べて少々の設定をするだけで、処理の設計が完了してしまいました。 実行してみましょう。
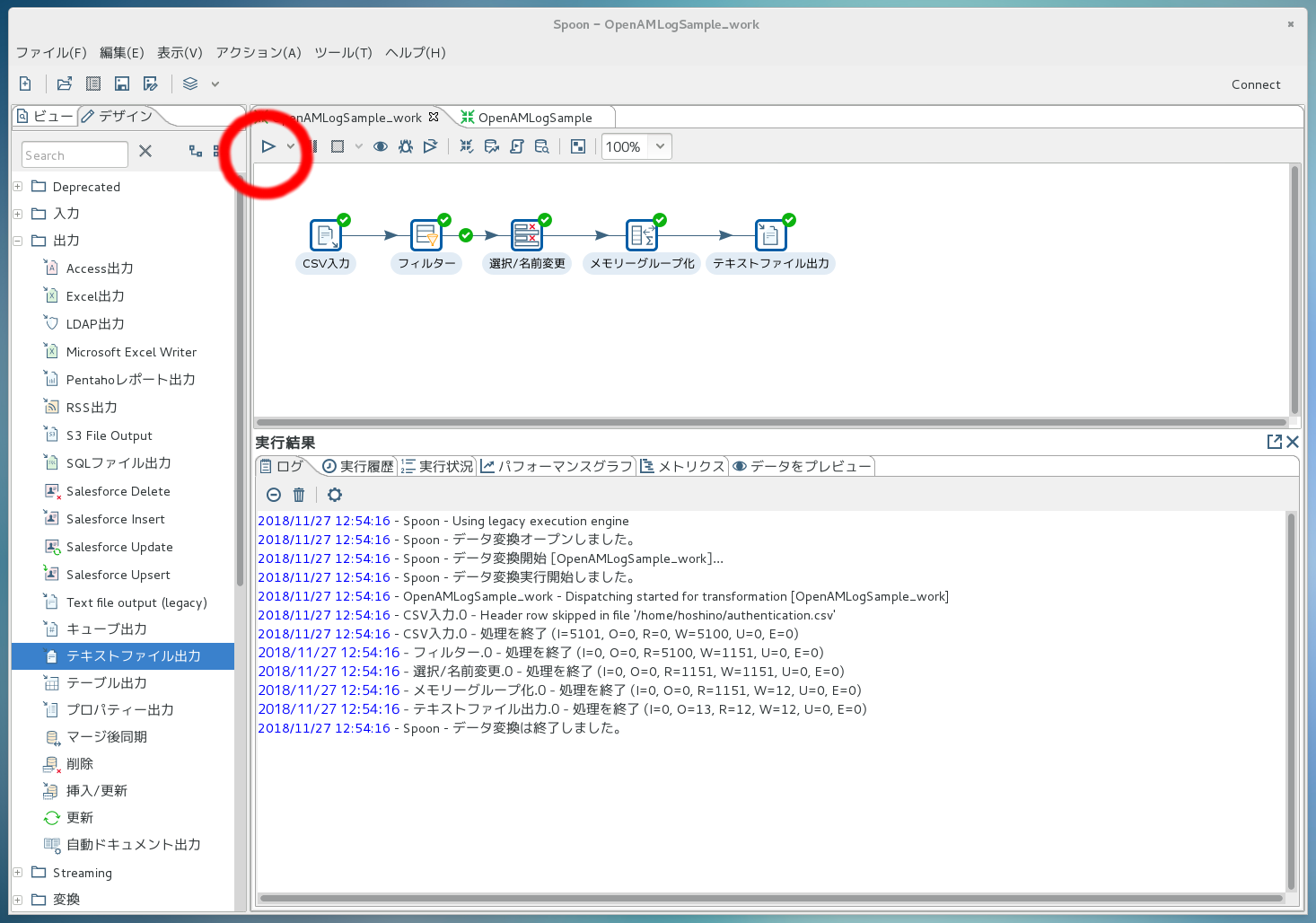
もちろんコマンドラインからも実行できますが、今回は設計画面上で実行してみます。 下の図の赤丸で囲まれているボタンを押すことで実行できます。
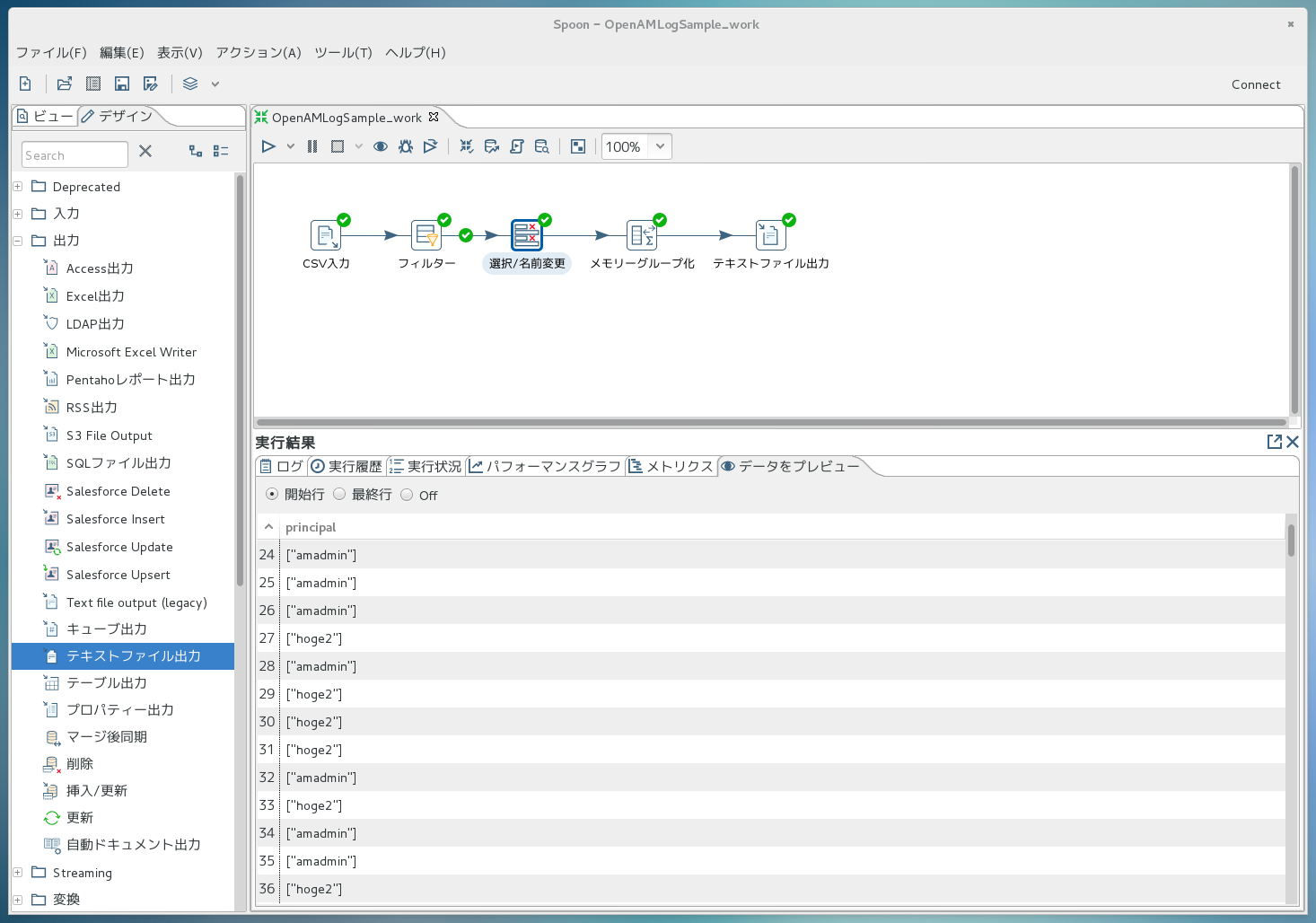
実行後、各処理部品を通過した際のデータを覗くこともできます。例えば、「principal列に絞り込んだけど、まだ集計処理はしていない」という段階のデータを見る場合は、「選択/名前変更」のアイコンをクリックするだけで下記の画面のように表示されます。複雑な処理を設計する際、デバッグがとても楽になります。
さて、実行した結果、出力されたファイルは…こんな感じでした。
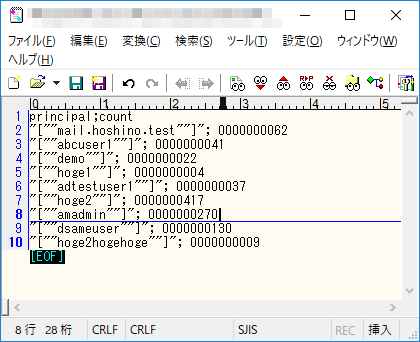
私のテスト環境では、hoge2さんがログイン回数トップで、417回だということがわかりました。
3. おわりに
以上のように、OpenAM 13のログをPentaho DIで処理することができました。
「これぐらい、スクリプト言語で書いてしまえばいいんじゃない?」という意見もあろうかと思います。 今回の例のような簡単な処理ならその通りですが、実際は入力ファイルがローテーションによって複数になってたり、実現したい処理が複雑だったりで、プログラミングしようとすると案外大変な作業になることがあります。 OSSのデータ処理ツールを使って、さくさく進めていきましょう。